
Der vorherige Artikel hat Ihnen einen Überblick über Hadoop und die beiden Komponenten von Hadoop gegeben, nämlich HDFS und das Mapreduce-Framework. In diesem Artikel erhalten Sie nun eine kurze Erläuterung der HDFS-Architektur und ihrer Funktionsweise.
HDFS:
Das Hadoop Distributed File System (HDFS) ist ein selbstheilender Clusterspeicher mit hoher Bandbreite. HDFS verfügt über eine Master/Slave-Architektur. Ein HDFS-Cluster besteht aus einem einzelnen NameNode, einem Masterserver, der den Dateisystem-Namespace verwaltet und den Zugriff auf Dateien durch Clients reguliert. Darüber hinaus gibt es eine Anzahl von Datenknoten, normalerweise einen pro Knoten im Cluster, der den Speicher verwaltet, der mit den Knoten verbunden ist, auf denen sie ausgeführt werden.
HDFS stellt einen Dateisystem-Namespace bereit und ermöglicht die Speicherung von Benutzerdaten in Dateien. Intern wird eine Datei in einen oder mehrere Blöcke aufgeteilt und diese Blöcke werden in einer Reihe von DataNodes gespeichert. Der NameNode führt Dateisystem-Namespace-Operationen wie das Öffnen, Schließen und Umbenennen von Dateien und Verzeichnissen aus.
Es bestimmt auch die Zuordnung von Blöcken zu DataNOdes. Die DataNodes sind für die Bearbeitung von Lese- und Schreibanforderungen der Clients des Dateisystems verantwortlich. Die DataNodes führen auf Anweisung des NameNode auch die Erstellung, Löschung und Replikation von Blöcken durch.
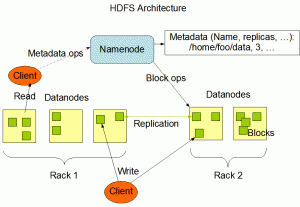
Die obige Skizze stellt die Architektur des HDFS dar.
Karte verkleinern:
Das andere Konzept und die andere Komponente von Hadoop ist Mapreduce. Mapreduce ist eine verteilte fehlertolerante Ressourcenverwaltung und -planung in Verbindung mit einer skalierbaren Abstraktion der Datenprogrammierung.
Es handelt sich um ein paralleles Datenverarbeitungs-Framework. Das Mapreduce-Framework wird verwendet, um die Daten aus den verschiedenen in einem System verfügbaren Dateien und Datenknoten abzurufen. Der erste Teil besteht darin, dass die Daten auf die verschiedenen Server übertragen werden müssen, wo die Dateien repliziert würden, kurz gesagt, sie dienen der Speicherung Daten.
Sobald die Daten gespeichert sind, besteht der zweite Schritt darin, den Code auf den Hadoop-Cluster zum Namensknoten zu übertragen, der auf verschiedene Datenknoten verteilt wird, die zu Rechenknoten werden, und dann würde der Endbenutzer die endgültige Ausgabe erhalten.
Mapreduce in Hadoop ist nicht nur die eine Funktion, die ausgeführt wird, es sind auch verschiedene Aufgaben beteiligt, wie z. B. Datensatzleser, Zuordnen, Kombinieren, Partitionieren, Mischen und Sortieren und Reduzieren der Daten und schließlich die Ausgabe der Ausgabe. Es teilt den Eingabedatensatz in unabhängige Blöcke auf, die von den Kartenaufgaben vollständig parallel verarbeitet werden.
Das Framework sortiert die Ausgaben der Karten, die dann als Eingabe an die reduzierten Aufgaben weitergegeben werden. Normalerweise werden sowohl die Eingabe als auch die Ausgabe des Jobs in einem Dateisystem gespeichert. Das Framework kümmert sich auch um die Planung und überwacht die erneute Ausführung der fehlgeschlagenen Aufgaben.
Mapreduce-Schlüssel-Wert-Paar:
Mapper und Reduzierer verwenden immer Schlüssel-Wert-Paare als Eingabe und Ausgabe. Ein Reduzierer reduziert Werte nur pro Schlüssel. Ein Mapper oder Reduzierer kann für jede Eingabe 0,1 oder mehr Schlüsselwertpaare ausgeben. Mapper und Reduzierer können beliebige Schlüssel oder Werte ausgeben, nicht nur Teilmengen oder Transformationen derjenigen in der Eingabe.
Beispiel:
Def Map (Schlüssel, Wert, Kontext)
value.to_s.split.each do |word|
word.gsub!(/W/, ”)
Wort.downcase!
es sei denn, word.empty?
context.write(Hadoop::Io::Text.new(word), Hadoop::Io::IntWritable.new(1))
Ende
Ende
Ende
def Reduce(Schlüssel, Werte, Kontext)
Summe = 0
Werte.each { |value| sum += value.get }
context.write(key, Hadoop::Io::IntWritable.new(sum))
Ende
Die Mapper-Methode teilt Leerzeichen auf, entfernt alle Nicht-Wort-Zeichen und Kleinbuchstaben. Als Wert wird eine Eins ausgegeben. Die Reduziermethode iteriert über die Werte, addiert alle Zahlen und gibt den Eingabeschlüssel und die Summe aus.
Eingabedatei: Hallo Welt, tschüss Welt
Ausgabedatei: Tschüss 1
Hallo 1
Welt 2
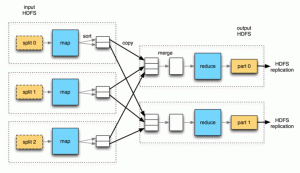
Damit endet das Briefing über die Komponenten von Hadoop, ihre Architektur, Funktionsweise und auch die Schritte, die an verschiedenen Prozessen beteiligt sind, die in beiden Systemen von Hadoop ablaufen.
Es gibt auch einige Vor- und Nachteile von Hadoop, ähnlich wie bei einer Münze, die aus zwei Seiten besteht, die in den kommenden Blogs besprochen werden. Eine vollständige Kenntnis eines Konzepts ist nur dann möglich, wenn Sie die Vor- und Nachteile des jeweiligen Konzepts kennen.
Um von nun an umfassende Kenntnisse über Hadoop zu erlangen, folgen Sie weiterhin den kommenden Beiträgen des Blogs.
Die zwei Gesichter von Hadoop
Vorteile:
- Hadoop ist eine Plattform, die sowohl verteilte Speicher- als auch Rechenfunktionen bietet.
- Hadoop ist extrem skalierbar. Tatsächlich war Hadoop das erste Unternehmen, das ein in Nutch bestehendes Skalierbarkeitsproblem beheben konnte – angefangen bei 1 TB/3 Knoten bis hin zu Petabyte/1000 Knoten.
- Eine der Hauptkomponenten von Hadoop ist HDFS (die Speicherkomponente), die für hohen Durchsatz optimiert ist.
- HDFS verwendet große Blockgrößen, was letztendlich hilft. Es funktioniert am besten bei der Bearbeitung großer Dateien (Gigabyte, Petabyte…).
- Skalierbarkeit und Verfügbarkeit sind die herausragenden Merkmale von HDFS, um ein Datenreplikations- und Fehlertoleranzsystem zu erreichen.
- HDFS kann Dateien für eine bestimmte Anzahl von Malen replizieren (Standard ist 3 Replikate), was Software- und Hardwarefehler toleriert. Darüber hinaus kann es Datenblöcke auf ausgefallenen Knoten automatisch erneut replizieren.
- Hadoop verwendet das MapReduce-Framework, ein stapelbasiertes, verteiltes Computing-Framework, das paralleles Arbeiten mit großen Datenmengen ermöglicht.
- MapReduce ermöglicht es den Entwicklern, sich ausschließlich auf die Erfüllung geschäftlicher Anforderungen zu konzentrieren, anstatt sich auf verteilte Systemkomplikationen einzulassen.
- Um eine parallele und schnellere Ausführung des Jobs zu erreichen, zerlegt MapReduce den Job in Map & Reduce-Aufgaben und plant sie für die Remote-Ausführung auf den Slave- oder Datenknoten des Hadoop-Clusters.
- Hadoop ist in der Lage, mit MR-Jobs zu arbeiten, die in anderen Sprachen erstellt wurden – dies wird als Streaming bezeichnet
- geeignet für die Analyse großer Datenmengen
- Amazons S3 ist hier die ultimative Quelle der Wahrheit und HDFS ist kurzlebig. Sie müssen sich keine Sorgen um Zuverlässigkeit usw. machen – Amazon S3 übernimmt das für Sie. Dies bedeutet auch, dass Sie in HDFS keinen hohen Replikationsfaktor benötigen.
- Sie können coole Archivierungsfunktionen wie Glacier nutzen.
- Außerdem zahlen Sie für die Rechenleistung nur dann, wenn Sie sie benötigen. Es ist bekannt, dass die meisten Hadoop-Installationen Schwierigkeiten haben, auch nur die 40%-Auslastung zu erreichen [3],[4]. Wenn Ihre Auslastung niedrig ist, kann das Hochfahren von Clustern bei Bedarf für Sie von Vorteil sein.
- Ein weiterer wichtiger Punkt ist, dass Ihre Arbeitsbelastung einige Spitzen aufweisen kann (z. B. am Ende der Woche oder des Monats) oder jeden Monat wächst. Sie können bei Bedarf größere Cluster starten und andernfalls bei kleineren bleiben.
- Sie müssen nicht ständig für Arbeitsspitzen vorsorgen. Ebenso müssen Sie Ihre Hardware nicht zwei bis drei Jahre im Voraus planen, wie es bei internen Clustern üblich ist. Sie können nach Belieben zahlen und nach Belieben wachsen. Dies reduziert das Risiko von Big-Data-Projekten erheblich.
- Ihre Verwaltungskosten können deutlich niedriger sein und Ihre Gesamtbetriebskosten reduzieren.
- Keine Vorabkosten für die Ausrüstung. Sie können beliebig viele Knoten so lange hochfahren, wie Sie sie benötigen, und sie dann herunterfahren. Es wird immer einfacher, Hadoop darauf auszuführen.
- Wirtschaftlichkeit – Kosten pro TB zu einem Bruchteil der herkömmlichen Optionen.
- Flexibilität – Speichern Sie beliebige Daten und führen Sie beliebige Analysen durch.
Nachteile:
- Wie Sie wissen, verwendet Hadoop HDFS und MapReduce. Beide Masterprozesse sind Single Points of Failure, obwohl derzeit aktiv an Hochverfügbarkeitsversionen gearbeitet wird.
- Bis zur Veröffentlichung von Hadoop 2.x werden HDFS und MapReduce Single-Master-Modelle verwenden, was zu Single Points of Failure führen kann.
- Sicherheit ist ebenfalls eines der Hauptanliegen, da Hadoop zwar ein Sicherheitsmodell bietet, dieses jedoch aufgrund seiner hohen Komplexität standardmäßig deaktiviert ist.
- Hadoop bietet keine Verschlüsselung auf Speicher- oder Netzwerkebene, was für Anwendungsdaten im öffentlichen Sektor ein großes Problem darstellt.
- HDFS ist für die Verarbeitung kleiner Dateien ineffizient und verfügt nicht über eine transparente Komprimierung. Da HDFS aufgrund seiner Optimierung für dauerhaften Durchsatz nicht für zufällige Lesevorgänge bei kleinen Dateien geeignet ist.
- MapReduce ist eine stapelbasierte Architektur, was bedeutet, dass es sich nicht für Anwendungsfälle eignet, die einen Echtzeit-Datenzugriff erfordern.
- MapReduce ist eine Shared-Nothing-Architektur, daher sind Aufgaben, die eine globale Synchronisierung oder die gemeinsame Nutzung veränderlicher Daten erfordern, nicht geeignet, was für einige Algorithmen eine Herausforderung darstellen kann.
- S3 ist nicht sehr schnell und die S3-Leistung von Vanilla Apache Hadoop ist nicht besonders gut. Wir bei Qubole haben einige Arbeiten an der Leistung von Hadoop mit dem S3-Dateisystem durchgeführt.
- Für S3 fallen natürlich eigene Speicherkosten an.
- Wenn Sie die Maschinen (oder Daten) über einen längeren Zeitraum behalten möchten, ist dies keine so wirtschaftliche Lösung wie ein physischer Cluster.
Hier endet das Briefing von Große Daten und Hadoop und seine verschiedenen Systeme und ihre Vor- und Nachteile. Ich wünschte, Sie hätten einen Überblick über das Konzept von Big Data und Hadoop bekommen.
Nehmen Sie Kontakt mit uns auf.
Manasa Heggere
Leitender Ruby on Rails-Entwickler



