L'articolo precedente ti ha fornito una panoramica di Hadoop e dei due componenti di Hadoop che sono HDFS e il framework Mapreduce. Questo articolo ora ti fornirà una breve spiegazione sull'architettura HDFS e sul suo funzionamento.
HDFS:
Il file system distribuito Hadoop (HDFS) è uno storage in cluster a larghezza di banda elevata con autoriparazione. HDFS ha un'architettura master/slave. Un cluster HDFS è costituito da un singolo NameNode, un server master che gestisce lo spazio dei nomi del file system e regola l'accesso ai file da parte dei client. Inoltre, nel cluster è presente un numero di datanode, solitamente uno per nodo, che gestisce lo spazio di archiviazione collegato ai nodi su cui vengono eseguiti.
HDFS espone uno spazio dei nomi del file system e consente di archiviare i dati dell'utente in file. Internamente un file viene suddiviso in uno o più blocchi e questi blocchi vengono archiviati in una serie di DataNode. Il NameNode esegue operazioni sullo spazio dei nomi del file system come l'apertura, la chiusura e la ridenominazione di file e directory.
Determina inoltre la mappatura dei blocchi sui DataNOde. I DataNode sono responsabili di servire le richieste di lettura e scrittura dai client del file system. I DataNode eseguono anche la creazione, l'eliminazione e la replica dei blocchi su istruzione del NameNode.
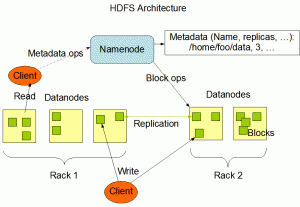
Lo schizzo sopra rappresenta l'architettura dell'HDFS.
Riduci mappa:
L'altro concetto e componente di Hadoop è Mapreduce. Mapreduce è una gestione e pianificazione distribuita delle risorse con tolleranza agli errori abbinata a un'astrazione di programmazione dei dati scalabile.
È un framework di elaborazione dati parallelo. Il framework Mapreduce viene utilizzato per estrarre i dati dai vari file e nodi di dati disponibili in un sistema. La prima parte è che i dati devono essere inseriti sui diversi server dove i file verranno replicati, in breve è archiviare il dati.
Il secondo passaggio, una volta archiviati i dati, il codice deve essere inviato al cluster Hadoop al namenode che verrebbe distribuito su diversi datanode che diventerebbero i nodi di calcolo e quindi l'utente finale riceverebbe l'output finale.
Mapreduce in Hadoop non è solo l'unica funzione attiva, ci sono diverse attività coinvolte come lettore di record, mappa, combinatore, partizionatore, mescola, ordina e riduce i dati e infine fornisce l'output. Suddivide il set di dati di input in blocchi indipendenti che vengono elaborati dalle attività della mappa in modo completamente parallelo.
Il framework ordina gli output delle mappe, che vengono poi inseriti come input per i compiti ridotti. In genere sia l'input che l'output del lavoro vengono archiviati in un file system. Il framework si occupa anche della pianificazione, monitorandoli e rieseguendo le attività fallite.
Coppia chiave-valore Mapreduce:
I mappatori e i riduttori utilizzano sempre coppie chiave-valore come input e output. Un riduttore riduce solo i valori per chiave. Un mappatore o un riduttore può emettere 0,1 o più coppie di valori chiave per ogni input. I mappatori e i riduttori possono emettere qualsiasi chiave o valore arbitrario, non solo sottoinsiemi o trasformazioni di quelli nell'input.
Esempio:
def map(chiave, valore, contesto)
valore.to_s.split.each fa |parola|
parola.gsub!(/W/, ")
parola.downcase!
a meno che word.empty?
context.write(Hadoop::Io::Text.new(parola), Hadoop::Io::IntWritable.new(1))
FINE
FINE
FINE
def ridurre(chiave, valori, contesto)
somma = 0
valori.ciascuno { |valore| somma += valore.get }
contesto.write(chiave, Hadoop::Io::IntWritable.new(somma))
FINE
Il metodo Mapper si divide sugli spazi bianchi, rimuove tutti i caratteri non verbali e le lettere minuscole. Restituisce uno come valore. Il metodo riduttore esegue l'iterazione sui valori, somma tutti i numeri e restituisce la chiave di input e la somma.
File di input: Ciao mondo, ciao mondo
file di uscita: Ciao 1
Ciao 1
Mondo 2
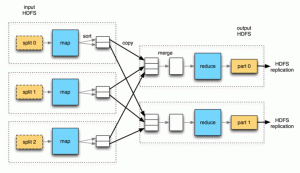
Qui termina il briefing sui componenti di Hadoop, la loro architettura, il funzionamento e anche le fasi coinvolte nei diversi processi che si verificano in entrambi i sistemi di Hadoop.
Ci sono anche alcuni pro e contro di Hadoop, analogamente a una moneta composta da due facce, di cui parleremo nei prossimi blog. La conoscenza completa di qualsiasi concetto può essere possibile solo una volta che si conoscono i meriti e i demeriti di quel particolare concetto.
D'ora in poi per acquisire una conoscenza completa di Hadoop continuate a seguire i prossimi post del blog.
I due volti di Hadoop
Professionisti:
- Hadoop è una piattaforma che fornisce sia funzionalità di archiviazione distribuita che computazionali.
- Hadoop è estremamente scalabile, infatti Hadoop è stato il primo considerato a risolvere un problema di scalabilità che esisteva in Nutch: inizia da 1 TB/3 nodi e aumenta fino a petabyte/migliaia di nodi.
- Uno dei componenti principali di Hadoop è HDFS (il componente di archiviazione) ottimizzato per un throughput elevato.
- HDFS utilizza blocchi di grandi dimensioni che, in definitiva, aiutano a funzionare meglio quando si manipolano file di grandi dimensioni (gigabyte, petabyte...).
- Scalabilità e disponibilità sono le caratteristiche distintive di HDFS per ottenere la replica dei dati e un sistema di tolleranza agli errori.
- HDFS può replicare i file per un numero specificato di volte (l'impostazione predefinita è 3 repliche) tollerando guasti software e hardware, inoltre può replicare automaticamente i blocchi di dati sui nodi che hanno fallito.
- Hadoop utilizza il framework MapReduce che è un framework di calcolo distribuito basato su batch, che consente il lavoro in parallelo su una grande quantità di dati.
- MapReduce consente agli sviluppatori di concentrarsi solo sulla soddisfazione delle esigenze aziendali, piuttosto che lasciarsi coinvolgere nelle complicazioni del sistema distribuito.
- Per ottenere un'esecuzione parallela e più rapida del lavoro, MapReduce scompone il lavoro in attività di mappatura e riduzione e le pianifica per l'esecuzione remota sullo slave o sui nodi dati del cluster Hadoop.
- Hadoop ha la capacità di lavorare con lavori MR creati in altre lingue: si chiama streaming
- adatto all’analisi dei big data
- S3 di Amazon è la massima fonte di verità in questo caso e HDFS è effimero. Non devi preoccuparti dell'affidabilità, ecc.: Amazon S3 se ne occupa per te. Significa anche che non è necessario un fattore di replica elevato in HDFS.
- Puoi sfruttare interessanti funzionalità di archiviazione come Glacier.
- Inoltre, paghi per l'elaborazione solo quando ne hai bisogno. È noto che la maggior parte delle installazioni Hadoop fatica a raggiungere anche l'utilizzo di 40% [3],[4]. Se il tuo utilizzo è basso, l'attivazione di cluster su richiesta potrebbe essere una soluzione vincente per te.
- Un altro punto chiave è che i tuoi carichi di lavoro potrebbero avere dei picchi (ad esempio alla fine della settimana o del mese) o potrebbero aumentare ogni mese. Puoi avviare cluster più grandi quando necessario e, altrimenti, restare con quelli più piccoli.
- Non è necessario prevedere continuamente il carico di lavoro di punta. Allo stesso modo, non è necessario pianificare l'hardware con 2-3 anni di anticipo, come è pratica comune con i cluster interni. Puoi pagare mentre procedi, crescere come preferisci. Ciò riduce notevolmente il rischio associato ai progetti Big Data.
- I costi amministrativi possono essere significativamente inferiori riducendo il TCO.
- Nessun costo anticipato per le attrezzature. Puoi avviare tutti i nodi che desideri, per tutto il tempo che ti servono, quindi spegnerli. Sta diventando più semplice eseguire Hadoop su di essi.
- Economia: costo per TB inferiore a quello delle opzioni tradizionali.
- Flessibilità: archivia qualsiasi dato, esegui qualsiasi analisi.
contro:
- Come sai, Hadoop utilizza HDFS e MapReduce, entrambi i processi principali sono singoli punti di errore, sebbene sia in corso un lavoro attivo per le versioni ad alta disponibilità.
- Fino al rilascio di Hadoop 2.x, HDFS e MapReduce utilizzeranno modelli a master singolo che possono causare singoli punti di errore.
- Anche la sicurezza è una delle maggiori preoccupazioni perché Hadoop offre un modello di sicurezza ma per impostazione predefinita è disabilitato a causa della sua elevata complessità.
- Hadoop non offre archiviazione o crittografia a livello di rete, il che rappresenta una grande preoccupazione per i dati delle applicazioni del settore governativo.
- HDFS è inefficiente per la gestione di file di piccole dimensioni e manca di una compressione trasparente. Poiché HDFS non è progettato per funzionare bene con letture casuali su file di piccole dimensioni a causa della sua ottimizzazione per un throughput sostenuto.
- MapReduce è un'architettura basata su batch, il che significa che non si presta a casi d'uso che richiedono l'accesso ai dati in tempo reale.
- MapReduce è un'architettura senza condivisione, pertanto le attività che richiedono la sincronizzazione globale o la condivisione di dati modificabili non sono adatte e possono rappresentare sfide per alcuni algoritmi.
- S3 non è molto veloce e le prestazioni S3 di Apache Hadoop vanilla non sono eccezionali. Noi di Qubole abbiamo lavorato sulle prestazioni di Hadoop con il filesystem S3.
- S3, ovviamente, ha i propri costi di archiviazione.
- Se vuoi conservare le macchine (o i dati) per un lungo periodo, non è una soluzione economica come un cluster fisico.
Qui termina il briefing di Grandi dati e Hadoop e i suoi vari sistemi e i loro pro e contro. Vorrei che tu avessi una panoramica del concetto di Big Data e Hadoop.
Manasa Heggere
Sviluppatore senior di Ruby on Rails