
前回の記事 Hadoop と、Hadoop の 2 つのコンポーネントである HDFS と Mapreduce フレームワークについての概要を説明しました。この記事では、HDFS アーキテクチャとその機能について簡単に説明します。
HDFS:
Hadoop 分散ファイル システム (HDFS) は、自己修復機能を備えた高帯域幅のクラスター化ストレージです。 HDFS にはマスター/スレーブ アーキテクチャがあります。 HDFS クラスターは、ファイル システムの名前空間を管理し、クライアントによるファイルへのアクセスを制御するマスター サーバーである単一の NameNode で構成されます。さらに、通常、クラスター内のノードごとに 1 つのデータノードがあり、データノードが実行されるノードに接続されたストレージを管理します。
HDFS はファイル システムの名前空間を公開し、ユーザー データをファイルに保存できるようにします。内部的には、ファイルは 1 つ以上のブロックに分割され、これらのブロックは一連の DataNode に格納されます。 NameNode は、ファイルやディレクトリを開いたり、閉じたり、名前を変更したりするなど、ファイル システムの名前空間操作を実行します。
また、ブロックの DataNOdes へのマッピングも決定します。データノードは、ファイル システムのクライアントからの読み取りおよび書き込みリクエストを処理する責任があります。 DataNode は、NameNode からの指示に応じて、ブロックの作成、削除、複製も実行します。
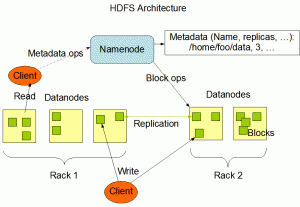
上のスケッチは、HDFS のアーキテクチャを表しています。
マップリデュース:
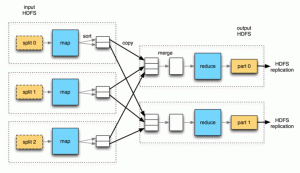
Hadoop のもう 1 つの概念およびコンポーネントは、Mapreduce です。 Mapreduce は、分散フォールトトレラントなリソース管理とスケジューリングを、スケーラブルなデータ プログラミング抽象化と組み合わせたものです。
並列データ処理フレームワークです。 Mapreduce フレームワークは、システム内で利用可能なさまざまなファイルやデータ ノードからデータを取得するために使用されます。最初の部分では、ファイルが複製される別のサーバーにデータをプッシュする必要があります。簡単に言うと、データ。
データが保存された後の 2 番目のステップでは、コードが Hadoop クラスターのネームノードにプッシュされ、計算ノードとなるさまざまなデータノードに分散され、エンドユーザーは最終出力を受け取ります。
Hadoop の Mapreduce は 1 つの機能だけでなく、レコード リーダー、マップ、コンバイナー、パーティショニング、シャッフル、ソート、データの削減などのさまざまなタスクが関与し、最終的に出力を提供します。入力データセットを独立したチャンクに分割し、マップ タスクによって完全に並列的に処理されます。
フレームワークはマップの出力をソートし、それらは削減されたタスクへの入力としてプッシュされます。通常、ジョブの入力と出力は両方ともファイル システムに保存されます。フレームワークはスケジューリングも処理し、失敗したタスクの再実行を監視します。
Mapreduce キーと値のペア:
マッパーとリデューサーは常にキーと値のペアを入力と出力として使用します。レデューサはキーごとの値のみを削減します。マッパーまたはリデューサーは、入力ごとに 0、1、またはそれ以上のキー値ペアを発行する場合があります。マッパーとリデューサーは、入力内のキーや値のサブセットや変換だけでなく、任意のキーや値を出力する場合があります。
例:
def マップ(キー、値、コンテキスト)
value.to_s.split.each は |word| を実行します
word.gsub!(/W/, ”)
word.小文字!
word.empty でなければ?
context.write(Hadoop::Io::Text.new(word), Hadoop::Io::IntWritable.new(1))
終わり
終わり
終わり
defreduce(キー、値、コンテキスト)
合計 = 0
値.それぞれ { |値|合計 += 値.get }
context.write(key, Hadoop::Io::IntWritable.new(sum))
終わり
マッパー メソッドは空白で分割し、単語以外の文字と小文字をすべて削除します。値として 1 を出力します。 Reducer メソッドは、値を反復処理してすべての数値を合計し、入力キーと合計を出力します。
入力ファイル: ハローワールド、バイワールド
出力ファイル: さようなら1
こんにちは1
ワールド2
これで、Hadoop のコンポーネント、そのアーキテクチャ、機能、および Hadoop の両方のシステムで発生するさまざまなプロセスに関連する手順についての説明は終了です。
Hadoop にも同様に、2 つの顔からなるコインのように、いくつかの長所と短所があり、これについては今後のブログで説明します。どのような概念であっても、その概念の長所と短所を理解することで初めて、その概念を完全に理解できるようになります。
今後、Hadoop に関する完全な知識を得るために、今後のブログの投稿をフォローし続けてください。
Hadoop の 2 つの顔
長所:
- Hadoop は、分散ストレージと計算機能の両方を提供するプラットフォームです。
- Hadoop は非常にスケーラブルです。実際、Hadoop は、Nutch に存在するスケーラビリティの問題を修正するために最初に検討されました。1 TB/3 ノードから始まり、ペタバイト/数千ノードまで拡張できます。
- Hadoop の主要コンポーネントの 1 つは、高スループット向けに最適化された HDFS (ストレージ コンポーネント) です。
- HDFS は大きなブロック サイズを使用するため、最終的には大きなファイル (ギガバイト、ペタバイトなど) を操作するときに最適に機能します。
- スケーラビリティと可用性は、データ レプリケーションとフォールト トレランス システムを実現するための HDFS の際立った機能です。
- HDFS は、ソフトウェアおよびハードウェアの障害に耐えられるように、指定された回数 (デフォルトは 3 レプリカ) ファイルを複製できます。さらに、障害が発生したノード上でデータ ブロックを自動的に再複製できます。
- Hadoop は、バッチベースの分散コンピューティング フレームワークである MapReduce フレームワークを使用し、大量のデータに対する並列作業を可能にします。
- MapReduce を使用すると、開発者は分散システムの複雑さに関与するのではなく、ビジネス ニーズに対処することだけに集中できます。
- ジョブの並列かつ高速な実行を実現するために、MapReduce はジョブを Map & Reduce タスクに分解し、Hadoop クラスターのスレーブまたはデータ ノードでリモート実行するようにスケジュールします。
- Hadoop には、他の言語で作成された MR ジョブを処理する機能があります。これはストリーミングと呼ばれます。
- ビッグデータの分析に適しています
- ここでは Amazon の S3 が究極の真実の情報源であり、HDFS は一時的なものです。信頼性などについて心配する必要はありません。Amazon S3 がそれを処理します。また、HDFS では高いレプリケーション係数が必要ないことも意味します。
- Glacier などの優れたアーカイブ機能を利用できます。
- また、必要な場合にのみコンピューティング料金を支払います。ほとんどの Hadoop インストールでは、40% の使用率にさえ達するのに苦労していることはよく知られています [3]、[4]。使用率が低い場合は、オンデマンドでクラスターをスピンアップする方が勝てる可能性があります。
- もう 1 つの重要なポイントは、ワークロードにスパイク (週末や月の終わりなど) があるか、毎月増加している可能性があることです。必要な場合はより大きなクラスターを起動し、それ以外の場合はより小さなクラスターを使用し続けることができます。
- ピーク時のワークロードに常にプロビジョニングする必要はありません。同様に、社内クラスタではよくあることですが、2 ~ 3 年前からハードウェアを計画する必要もありません。従量課金制で、好きなだけ成長できます。これにより、ビッグデータ プロジェクトに伴うリスクが大幅に軽減されます。
- 管理コストが大幅に削減され、TCO が削減されます。
- 設備の初期費用はかかりません。必要なだけノードを必要なだけスピンアップし、その後シャットダウンできます。それら上で Hadoop を実行するのが簡単になってきています。
- 経済性 – 従来のオプションの数分の一での TB あたりのコスト。
- 柔軟性 – あらゆるデータを保存し、あらゆる分析を実行します。
短所:
- ご存知のとおり、Hadoop は HDFS と MapReduce を使用しており、高可用性バージョンに向けた作業が活発に行われていますが、両方のマスター プロセスが単一障害点になります。
- Hadoop 2.x リリースまで、HDFS と MapReduce は単一マスター モデルを使用するため、単一障害点が発生する可能性があります。
- Hadoop はセキュリティ モデルを提供しますが、非常に複雑なため、デフォルトでは無効になっているため、セキュリティも大きな懸念事項の 1 つです。
- Hadoop は、政府部門のアプリケーション データにとって大きな懸念となるストレージ レベルやネットワーク レベルの暗号化を提供しません。
- HDFS は小さなファイルの処理には非効率であり、透過的な圧縮機能がありません。 HDFS は持続的なスループットを最適化するため、小さなファイルのランダム読み取りで適切に動作するように設計されていません。
- MapReduce はバッチベースのアーキテクチャであるため、リアルタイムのデータ アクセスが必要なユースケースには適していません。
- MapReduce はシェアードナッシング アーキテクチャであるため、グローバル同期や可変データの共有を必要とするタスクには適しておらず、一部のアルゴリズムに課題が生じる可能性があります。
- S3 はそれほど高速ではなく、バニラの Apache Hadoop の S3 パフォーマンスはそれほど高くありません。私たち Qubole では、S3 ファイルシステムを使用した Hadoop のパフォーマンスについていくつかの作業を行いました。
- もちろん、S3 には独自のストレージ コストがかかります。
- マシン (またはデータ) を長期間維持したい場合、物理クラスターほど経済的なソリューションではありません。
以上で説明会を終了します ビッグデータ Hadoop とそのさまざまなシステムとその長所と短所。ビッグ データと Hadoop の概念について概要を理解していただければ幸いです。
マナサ・ヘゲレ
Ruby on Rails シニア開発者



