
Förra artikeln har gett dig en översikt om Hadoop och de två komponenterna i Hadoop som är HDFS och Mapreduce-ramverket. Den här artikeln skulle nu ge dig en kort förklaring om HDFS-arkitekturen och dess funktion.
HDFS:
Hadoop Distributed File System (HDFS) är självläkande klustrad lagring med hög bandbredd. HDFS har en master/slav-arkitektur. Ett HDFS-kluster består av en enda NameNode, en huvudserver som hanterar filsystemets namnutrymme och reglerar åtkomst till filer för klienter. Dessutom finns det antal datanoder vanligtvis en per nod i klustret, som hanterar lagringen kopplad till noderna som de körs på.
HDFS exponerar ett filsystems namnutrymme och tillåter att användardata lagras i filer. Internt delas en fil i ett eller flera block och dessa block lagras i en uppsättning DataNodes. NameNode utför filsystemets namnområdesoperationer som att öppna, stänga och byta namn på filer och kataloger.
Den bestämmer också mappningen av block till DataNOdes. DataNoderna ansvarar för att betjäna läs- och skrivförfrågningar från filsystemets klienter. DataNoderna utför också blockskapande, radering och replikering efter instruktioner från NameNode.
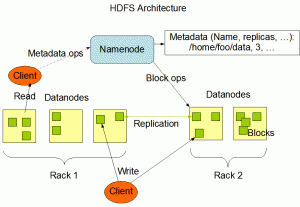
Ovanstående skiss representerar arkitekturen för HDFS.
MapReduce:
Det andra konceptet och komponenten i Hadoop är Mapreduce. Mapreduce är distribuerad feltolerant resurshantering och schemaläggning i kombination med en skalbar dataprogrammeringsabstraktion.
Det är ett parallellt ramverk för databehandling. Mapreduce-ramverket används för att få ut data från de olika filerna och datanoderna som finns tillgängliga i ett system. Den första delen är att data måste skjutas in på de olika servrarna där filerna replikeras. Det är kort sagt att lagra data.
Det andra steget när data har lagrats ska koden skjutas till Hadoop-klustret till namnnoden som skulle distribueras på olika datanoder som skulle bli beräkningsnoderna och sedan skulle slutanvändaren ta emot den slutliga utmatningen.
Mapreduce i Hadoop är inte bara den enda funktionen som händer, det finns olika uppgifter inblandade som postläsare, map, combiner, partition-er, blanda och sortera och reducera data och slutligen ger utdata. Den delar upp indatauppsättningen i oberoende bitar som bearbetas av kartuppgifterna på ett helt parallellt sätt.
Ramverket sorterar kartornas utdata, som sedan pushas som en input till de reducerade uppgifterna. Vanligtvis lagras både indata och utdata från jobbet i ett filsystem. Ramverket tar också hand om schemaläggning, övervakar dem och utför de misslyckade uppgifterna igen.
Mapreduce nyckel-värde-par:
Kartläggare och reducerare använder alltid nyckel-värdepar som input och output. En reducering reducerar endast värden per nyckel. En mappare eller reducerare kan sända ut 0,1 eller fler nyckelvärdespar för varje ingång. Kartläggare och reducerare kan sända ut godtyckliga nycklar eller värden, inte bara delmängder eller transformationer av dem i inmatningen.
Exempel:
def map(nyckel, värde, sammanhang)
värde.till_s.split.varje gör |ord|
word.gsub!(/W/, ”)
word.downcase!
om inte word.tomt?
context.write(Hadoop::Io::Text.new(word), Hadoop::Io::IntWritable.new(1))
slutet
slutet
slutet
def reduce(nyckel, värden, sammanhang)
summa = 0
värden.varje { |värde| summa += värde.get }
context.write(key, Hadoop::Io::IntWritable.new(sum))
slutet
Mapper-metoden delar på blanksteg, tar bort alla tecken som inte är ord och små bokstäver. Den matar ut en etta som värde. Reducermetoden är att iterera över värdena, lägga ihop alla siffror och mata ut inmatningsnyckeln och summan.
Indatafil: Hej världen Bye World
utdatafil: Hejdå 1
Hej 1
Värld 2
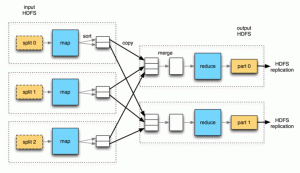
Därav slutar genomgången om komponenterna i Hadoop, deras arkitektur, funktion och även steg involverade i olika processer som sker i båda systemen i Hadoop.
Det finns också några för- och nackdelar med Hadoop på samma sätt som ett mynt som består av två ansikten som kommer att diskuteras i de kommande bloggarna. Fullständig kunskap om vilket koncept som helst kan bara vara möjligt när du får veta mer och nackdelar med det specifika konceptet.
För att få fullständig kunskap om Hadoop fortsätt följa bloggens kommande inlägg.
Hadoops två ansikten
Fördelar:
- Hadoop är en plattform som erbjuder både distribuerad lagring och beräkningsmöjligheter.
- Hadoop är extremt skalbart, Hadoop var faktiskt den första som ansågs fixa ett skalbarhetsproblem som fanns i Nutch – Börja med 1TB/3-noder växa till petabyte/1000-tals noder.
- En av huvudkomponenterna i Hadoop är HDFS (lagringskomponenten) som är optimerad för hög genomströmning.
- HDFS använder stora blockstorlekar som i slutändan hjälper. Det fungerar bäst när man manipulerar stora filer (gigabyte, petabyte...).
- Skalbarhet och tillgänglighet är de utmärkande egenskaperna hos HDFS för att uppnå datareplikering och feltoleranssystem.
- HDFS kan replikera filer ett visst antal gånger (standard är 3 repliker) som är tolerant mot mjukvaru- och hårdvarufel. Dessutom kan den automatiskt replikera datablock på noder som har misslyckats.
- Hadoop använder MapReduce-ramverket som är ett batchbaserat, distribuerat datorramverk, det tillåter parallellt arbete över en stor mängd data.
- MapReduce låter utvecklarna fokusera på att bara tillgodose affärsbehov, snarare än att engagera sig i distribuerade systemkomplikationer.
- För att uppnå parallell och snabbare exekvering av jobbet, bryter MapReduce ner jobbet i Map & Reduce-uppgifter och schemalägger dem för fjärrexekvering på Hadoop-klustrets slav- eller datanod.
- Hadoop do har förmågan att arbeta med MR-jobb skapade på andra språk – det kallas streaming
- lämpad för att analysera big data
- Amazons S3 är den ultimata källan till sanning här och HDFS är tillfällig. Du behöver inte oroa dig för tillförlitlighet etc – Amazon S3 tar hand om det åt dig. Betyder också att du inte behöver hög replikeringsfaktor i HDFS.
- Du kan dra nytta av coola arkiveringsfunktioner som Glacier.
- Du betalar också bara för beräkning när du behöver det. Det är välkänt att de flesta Hadoop-installationer kämpar för att nå ens 40%-användning [3],[4]. Om ditt utnyttjande är lågt kan det vara en vinnare för dig att skapa kluster på begäran.
- En annan viktig punkt är att din arbetsbelastning kan ha vissa toppar (säg i slutet av veckan eller månaden) eller kan växa varje månad. Du kan starta större kluster när du behöver och hålla dig till mindre annars.
- Du behöver inte ta hänsyn till hög arbetsbelastning hela tiden. På samma sätt behöver du inte planera din hårdvara 2-3 år i förväg, vilket är vanligt med interna kluster. Du kan betala när du går, växa som du vill. Detta minskar risken med Big Data-projekt avsevärt.
- Dina administrationskostnader kan vara betydligt lägre och minska din TCO.
- Inga utrustningskostnader i förväg. Du kan snurra upp så många noder du vill, så länge du behöver dem, och sedan stänga av den. Det blir lättare att köra Hadoop på dem.
- Ekonomi – Kostnad per TB till en bråkdel av traditionella alternativ.
- Flexibilitet – Lagra all data, kör vilken analys som helst.
nackdelar:
- Som ni vet använder Hadoop HDFS och MapReduce, båda deras huvudprocesser är enstaka felpunkter, även om det pågår aktivt arbete för versioner med hög tillgänglighet.
- Fram till Hadoop 2.x-versionen kommer HDFS och MapReduce att använda single-master-modeller som kan resultera i enstaka felpunkter.
- Säkerhet är också ett av de största problemen eftersom Hadoop erbjuder en säkerhetsmodell, men som standard är den inaktiverad på grund av dess höga komplexitet.
- Hadoop erbjuder inte lagrings- eller nätverksnivåkryptering, vilket är mycket stort bekymmer för applikationsdata från statlig sektor.
- HDFS är ineffektivt för att hantera små filer och det saknar transparent komprimering. Eftersom HDFS inte är utformad för att fungera bra med slumpmässiga läsningar över små filer på grund av dess optimering för ihållande genomströmning.
- MapReduce är en batch-baserad arkitektur som innebär att den inte lämpar sig för användningsfall som behöver dataåtkomst i realtid.
- MapReduce är en delad-ingenting-arkitektur, därför passar uppgifter som kräver global synkronisering eller delning av föränderlig data inte bra, vilket kan innebära utmaningar för vissa algoritmer.
- S3 är inte särskilt snabb och vanilla Apache Hadoops S3-prestanda är inte bra. Vi på Qubole har jobbat lite med Hadoops prestanda med S3 filsystem.
- S3 kommer naturligtvis med sin egen lagringskostnad .
- Om du vill ha kvar maskinerna (eller data) länge är det inte en lika ekonomisk lösning som ett fysiskt kluster.
Här slutar genomgången av Big Data och Hadoop och dess olika system och deras för- och nackdelar. Önskar att du hade fått en överblick över konceptet Big Data och Hadoop.
Manasa Heggere
Senior Ruby on Rails-utvecklare



